在 opencv 3.0
createBackgroundSubtractorMOG()
已經被 createBackgroundSubtractorMOG2()取代
BackgroundSubtractorMOG2
It is also a Gaussian Mixture-based Background/Foreground Segmentation Algorithm. It is based on two papers by Z.Zivkovic, “Improved adaptive Gausian mixture model for background subtraction” in 2004 and “Efficient Adaptive Density Estimation per Image Pixel for the Task of Background Subtraction” in 2006. One important feature of this algorithm is that it selects the appropriate number of gaussian distribution for each pixel. (Remember, in last case, we took a K gaussian distributions throughout the algorithm). It provides better adaptibility to varying scenes due illumination changes etc.
As in previous case, we have to create a background subtractor object. Here, you have an option of selecting whether shadow to be detected or not. If detectShadows = True (which is so by default), it detects and marks shadows, but decreases the speed. Shadows will be marked in gray color.
========================================
import sys
sys.path.append('/usr/local/lib/python2.7/site-packages')
import numpy as np
import cv2
cap = cv2.VideoCapture('../src.avi')
#fgbg = cv2.createBackgroundSubtractorMOG()
fgbg = cv2.createBackgroundSubtractorMOG2()
while(1):
ret, frame = cap.read()
if(ret == False):
break
fgmask = fgbg.apply(frame)
cv2.imshow('frame',fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
======================================
Reference : http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_video/py_bg_subtraction/py_bg_subtraction.html#py-background-subtraction
BackgroundSubtractorGMG
This algorithm combines statistical background image estimation and per-pixel Bayesian segmentation. It was introduced by Andrew B. Godbehere, Akihiro Matsukawa, Ken Goldberg in their paper “Visual Tracking of Human Visitors under Variable-Lighting Conditions for a Responsive Audio Art Installation” in 2012. As per the paper, the system ran a successful interactive audio art installation called “Are We There Yet?” from March 31 - July 31 2011 at the Contemporary Jewish Museum in San Francisco, California.
It uses first few (120 by default) frames for background modelling. It employs probabilistic foreground segmentation algorithm that identifies possible foreground objects using Bayesian inference. The estimates are adaptive; newer observations are more heavily weighted than old observations to accommodate variable illumination. Several morphological filtering operations like closing and opening are done to remove unwanted noise. You will get a black window during first few frames.
It would be better to apply morphological opening to the result to remove the noises.
Original Frame
Below image shows the 200th frame of a video

Result of BackgroundSubtractorMOG
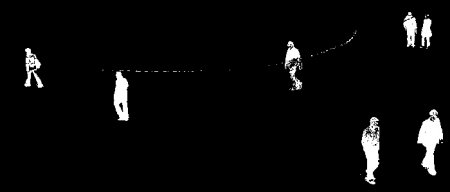
Result of BackgroundSubtractorMOG2
Gray color region shows shadow region.

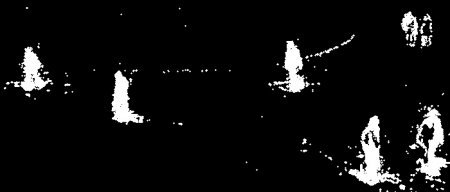
Result of BackgroundSubtractorGMG
Noise is removed with morphological opening.
Reference : http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_video/py_bg_subtraction/py_bg_subtraction.html#py-background-subtraction
沒有留言:
張貼留言